levedb是什么 Link to heading
官方解释
LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values.
解决的问题 Link to heading
写多余读的场景
提供的核心能力 Link to heading
具备的能力 Link to heading
- 键值是任意字节数组
- 按key有序&可自定义排序方法
- 核心操作 Put,Get,Delete
- 批量操作
- 快照
- 遍历
- 数据压缩
- 对外交互通过虚拟层进行,用户可以自定义操作系统层功能(External activity (file system operations etc.) is relayed through a virtual interface so users can customize the operating system interactions.)
不具备的能力 Link to heading
- 非SQL数据库,没有关系数据模型,不支持SQL查询,不支持索引
- 只支持单进程模式(多线程)
- 只是个lib库,没有现成可以使用的client-server,需要自己封装
资源结构依赖 Link to heading
lib库,需要和其它系统配合使用,可以参考bigtable
架构 Link to heading
数据结构 Link to heading
核心数据结构 Link to heading
- MemTable
- 介绍
- 内存中的数据存储结构,所有的数据都会先写入MemTable,再经过compaction到文件中
- 介绍
- MemTableIterator
- 介绍
- 内存中MemTable的遍历结构
- 介绍
- SkipList
- 介绍
- 内存中的数据存储结构,读写复杂度 O(logn)
- 介绍
- Table
- 介绍
- 文件的数据存储结构,是一个按key有序的map,不可变
- 介绍
- TableBuilder
- 介绍
- 封装写文件相关方法
- 介绍
- BlockBuilder
- 介绍
- 封装文件中 data block、meta block等写block信息
- 介绍
- BlockHandle
- 介绍
- 是一个文件指针,指向文件中某个data block或者meta block,用offset以及size对block进行标识
- 介绍
- Version
- 介绍
- 记录DB的版本信息,数据结构上是一个双链表
- 介绍
其它数据结构 Link to heading
算法/过程 Link to heading
compaction Link to heading
分为三个阶段
- 内存中的memtable转换为immutable memtable
- immutable memtable → level 0 文件
- level N → level N+1 文件合并
内存阶段
操作
-
内存中正在写的memtable 变为 immutable memtable
- 如下进行指针替换
1 2 3 4 5// db/db_impl.cc imm_ = mem_; // 当前写满的memtable赋值给immutable memtable has_imm_.store(true, std::memory_order_release); mem_ = new MemTable(internal_comparator_); // 新建一个memtable mem_->Ref(); // 赋给当前写入的memtable指针
触发条件
- DBImpl::Put、DBImpl::Delete 过程 如果当前memtable写满
内存到文件阶段 minor compaction
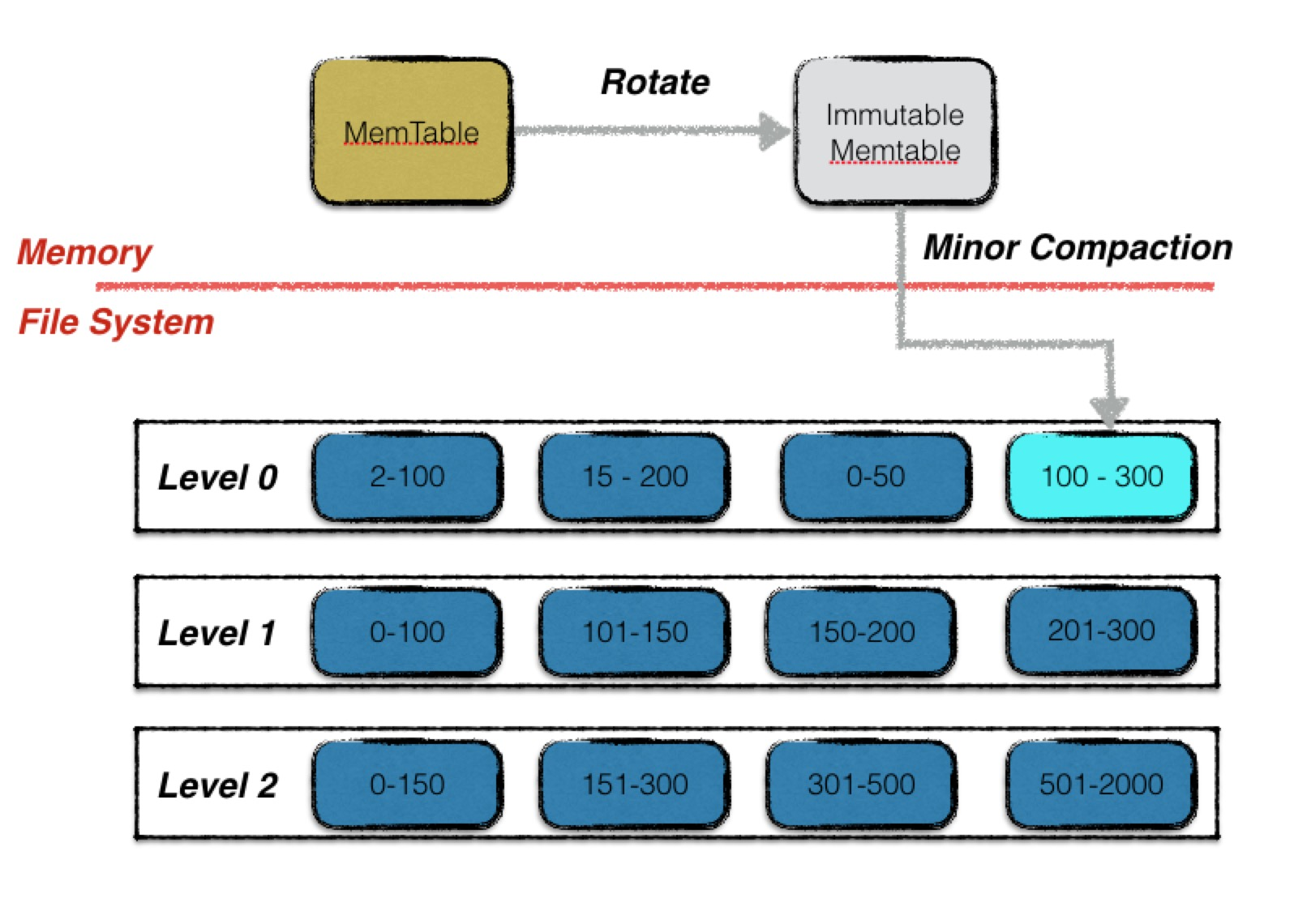
内存数据格式
|
|
解释
- 最底层是一个有序链表
- 为了加快单链表的查询速度,在单链表之上增加了多层查询链接,用于快速跳过大部分节点,将查询效率从O(n)降低为O(log n)
文件数据格式
|
|
解释
-
kv键值对按序被放置在data blocks中,所有data block被从文件开头开始连续的排列在一起。每一个data block使用
block_builder.cc中的代码进行格式化处理,并进行选择性的压缩。 -
data blocks之后是meta blocks。所有的 meta blocks如下所示。未来会添加更多的meta blocks类型,每个 meta block也使用 block_builder.cc 进行格式化处理以及选择性的压缩。
-
“filter” Meta Block
如果open时传入了
FilterPolicy,那么每个磁盘文件就会有这么一个 filter block。TBD: https://github.com/google/leveldb/blob/master/doc/table_format.md -
“stats” Meta Block 暂未实现
存储以下信息
1 2 3 4 5 6data size index size key size (uncompressed) value size (uncompressed) number of entries number of data blocks
-
-
metaindex block. 包含meta block的索引信息,key为meta block的名称,value为对应的 BlockHandle
-
index block. 包含每个data block的索引信息,每个data block中有一个条目,key为一个 string, 该string为对应data block中的最大key值,value为对应的BlockHandle
-
最后是大小固定的footer block,包含metaindex和index的BlockHandle、zero填充用字节以及一个幻数(用于快速识别文件格式)
-
幻数:const uint64_t kTableMagicNumber = 0xdb4775248b80fb57ull;
kTableMagicNumber was picked by running echo http://code.google.com/p/leveldb/ | sha1sum and taking the leading 64 bits.
-
操作
- BackgroundCompaction immutable memtable dump成level 0的sstable(sorted set table)
-
DBImpl::CompactMemTable 优先进行内存到文件的 minor compaction;完成后直接return
原因:TBD?
- DBImpl::WriteLevel0Table
- 获取下一个文件名
versions_ -> NewFileNumber() - 内存到文件的转换
BuildTable- 使用iter遍历memtable
TablerBuilder.Add添加到文件中- 写入 data block
TableBuilder::Finish按如下顺序写对应的block信息- meta block (filter)
- metaindex block
- index block
- footer
- 确保持久化到磁盘中
file -> Sync() - 最后进行错误检查
- 获取下一个文件名
- DBImpl::WriteLevel0Table
-
再进行 major compaction
-
触发条件
-
在BackgroundCompaction中进行,如下阶段会尝试进行Compaction
核心思路:compaction由文件状态变化触发(查询也会触发文件状态的变化),没有文件状态的变化只需要在打开BD时进行一次compaction即可,无需一个定时任务进行触发。
- DBImpl::Get阶段 如果内存中没查询到且文件中查询到了
- 🤔 优化点:用某个文件的seeks次数信息决定下一次compact的文件
- 原因:将热点文件尽快compact到下一层?TBD
- 🤔 优化点:用某个文件的seeks次数信息决定下一次compact的文件
- DBImpl::Put、DBImpl::Delete 过程 如果当前memtable写满
- DB::Open 阶段,db打开阶段
- 一次BackgroundCompaction结束后,递归调用BackgroundCompaction
- 原因:Previous compaction may have produced too many files in a level,so reschedule another compaction if needed.
- DBImpl::Get阶段 如果内存中没查询到且文件中查询到了
level N → level N+1 文件合并 major compaction
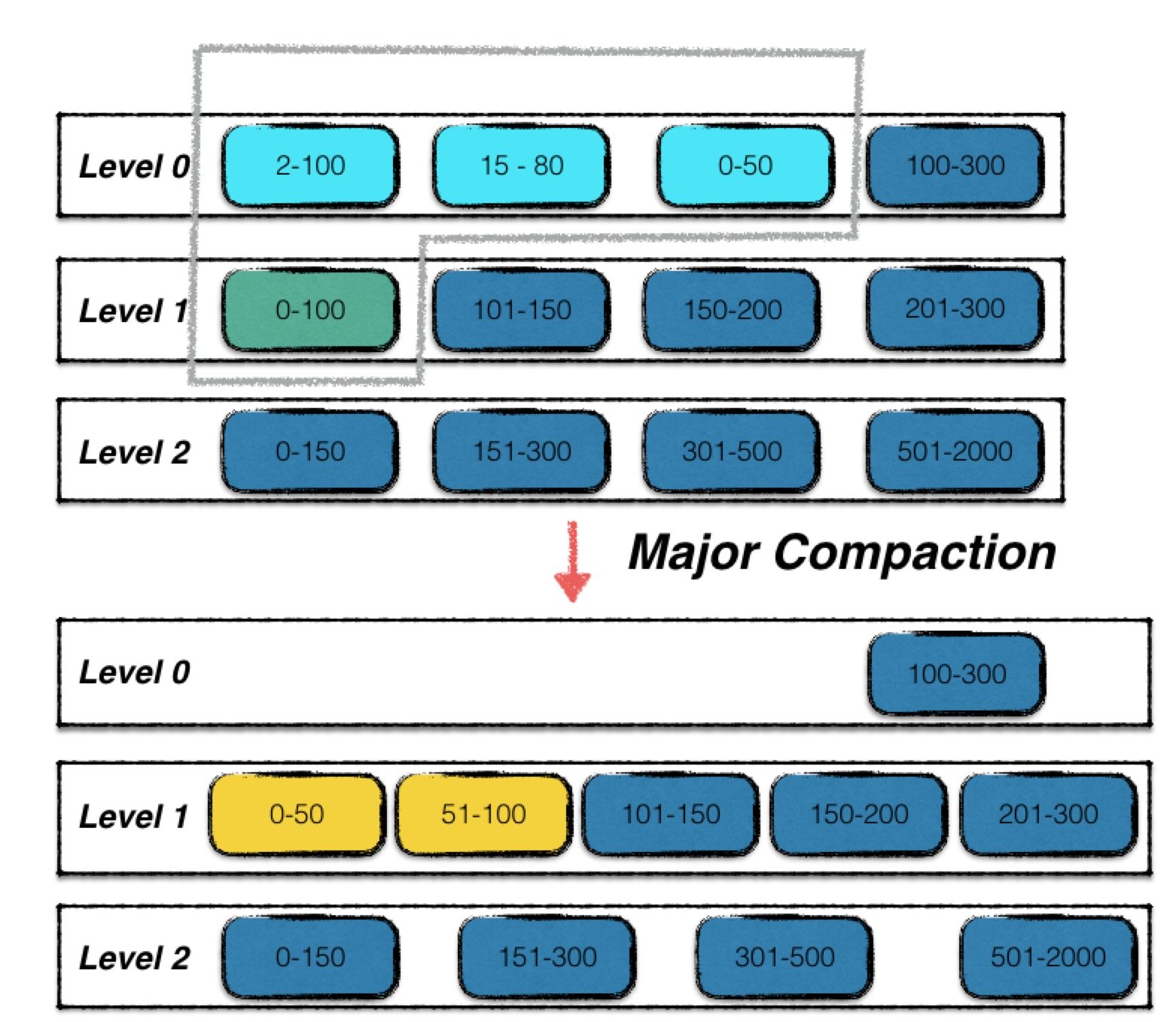
操作
DBImpl::BackgroundCompaction进行compactionDBImpl::CompactMemTable优先进行minor compaction 将内存中的immutable memtable 写到level 0的文件中- 再进行major compaction
versions_->PickCompaction()组装本次compaction的相关信息- 需要确定的信息
- 本次compaction发生在哪个level
- 确定level后 确定level中的哪个文件进行compaction
- 判断逻辑
- 优先判断level中的数据大小是否超过阈值
current_->compaction_score_ >= 1判断当前是否存在某level实际存储数据已经超过设定的阈值,level 1: 10M level 2: 100M 。。。level 6: 1T- 对于level 0特殊处理,不是根据该层数据大小,而是根据level 0层文件数,依据如下两个原因
- version_set.cc:1033 TBD
- 对于最后一层不进行判断,最后一层理论上可以存储无限多的数据
- 对于level 0特殊处理,不是根据该层数据大小,而是根据level 0层文件数,依据如下两个原因
- 确定好compaction的level后,挑选进行compaction的文件
compact_pointer_[config::kNumLevels]存储历史上进行compaction的file,按文件轮流进行compaction,确保每个文件都能进行compaction
- 没有超过阈值的对访问热点(通过seek_times)的文件进行compaction,🤔 这个优化点TBD
- 优先判断level中的数据大小是否超过阈值
- 需要确定的信息
DBImpl::DoCompactionWork
其它算法/过程 Link to heading
关系 Link to heading
TBD
核心关系 Link to heading
TBD
其它关系 Link to heading
TBD
API Link to heading
核心API Link to heading
Get Link to heading
找到对应key,且sequenceNumber最大的value
- 过程描述
- mem(memtable using) MemTable::Get 在当前内存 memtable 中搜索
- imm (Memtable being compacted)MemTable::Get 在当前内存 memtable 中搜索
- current Status Version::Get 文件搜索
- ForEachOverlapping
- level 0
- 比较所有文件大小两端值 找到所有可能有该key的 level 0
- 遍历上述文件
- level 0
- ForEachOverlapping
Put Link to heading
- 过程描述
- MakeRoomForWrite 确保有空间写入
- 循环检测db状态 按优先级排序
- 检测到错误直接返回
- kL0_SlowdownWritesTrigger = 8 (Soft limit on number of level-0 files. We slow down writes at this point.)
- sleep 1ms;写入降速,避免出现毛刺
- 检测当前 memtable 是否有空间,是则允许该次写入,当前memtable空间大小
size_t write_buffer_size = 4 * 1024 * 1024 - 检测当前是否有memtable正在进行minor compaction,是则等待完成
- kL0_StopWritesTrigger = 12 (Maximum number of level-0 files. We stop writes at this point.),是则等待major compaction完成以减少level 0文件数量
- 新建log、新建 memtable 、 触发compaction (走到这里标识当前memtable被写满)
- 新文件名
VersionSet::next_file_number_++ - 新memtable
- 尝试触发compaction 按优先级排序
- 检测是否已经触发了
- 检测DB是否正在被删除 无需进行compaction
- 检测是否有错误
- 检测是否满足compaction前置条件
- schedule compaction
- 新文件名
- 循环检测db状态 按优先级排序
- WriteBatch SequenceNumber 版本号+1
- Append log_->AddRecord 写日志
- 按 options.sync 配置写文件: fsync (每次写入都fsync对性能影响极大,但数据不会丢)
- WriteBatchInternal::InsertInto 写内存 memtable
- MakeRoomForWrite 确保有空间写入
- 优化点
- leveldb中写操作不是瓶颈,但写过多会影响读的效率;所以会有一些列策略限制写
- 写多了会造成文件过多,从而使得查找需要大量IO,因为查文件需要检查一遍start、end
- leveldb中写操作不是瓶颈,但写过多会影响读的效率;所以会有一些列策略限制写
详细过程
原因
- Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value)
- WriteBatch batch; batch.Put(key, value);
- return DBImpl::Write(const WriteOptions& options, WriteBatch* updates)
- new writer
- MutexLock 上锁
- writes进队列
Delete Link to heading
List/Iteration 遍历 Link to heading
Snapshot Link to heading
其它API Link to heading
参考 Link to heading
- 源码版本 https://github.com/google/leveldb 5bd5f0f67a5eb0ed74c16b3ae847ec4e5bc3e412
- http://smalldatum.blogspot.com/2018/06/the-original-lsm-paper.html
- https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
- https://yuerblog.cc/wp-content/uploads/leveldb实现解析.pdf
- https://github.com/google/leveldb/blob/master/doc/table_format.md
- https://leveldb-handbook.readthedocs.io/zh/latest/compaction.html