abstract 摘要 Link to heading
略
introduction 介绍 Link to heading
略
Data Model 数据模型 Link to heading
简述 Link to heading
- BigTable是一个稀疏、分布式、持久化、多维度的有序Map
- map的key含三个维度:row key、column key及时间戳,map的value是任意字节数组
- 整个Map结构: (row:string, column:string, time:int64) → string
- 如何得出这个结构的?潜在的使用需求分析
rows Link to heading
- 原子操作在row key这个维度,无论其中有多少个columns在读写,降低实现&使用复杂度
- row key 排序,按照 lexicographic order 字典序
- 多个连续的row组成一个row range,为一个tablet,一个table被动态分割成多个tablet,tablet是系统分布和负载均衡的单元
- client可以根据排序特性设计row key以提供更好的局部性,因为排序上越靠近的row key,物理存储位置在一起的可能性会越高,因此范围读取速度也会更快
Column Families Link to heading
- 相同column key会被分到同一组,成为column families, 是一个访问控制单元 basic unit of access control
- 在同一个column familiy的column key通常数据类型相同,会一起压缩
- column family必须提前创建,为啥呢
- 控制总 column families 数量 在百个级别
- 减少运维中的column family变更
- 与此相对应的是,column key的数量不受限制
- column key的格式为 family:qualifier, family必须是可打印的字符,但qualifier可以是任意字节
- 访问控制(access control)以及disk、memory的账单计费等,都在 column-family 这一层;通过访问控制,可以管理不同类型的数据,有的可以新增base数据,有的只能读base数据,然后基于base数据再新增派生的数据等等
Timestamps Link to heading
- 每个cell(由row key和column key定位)中可以存储一份数据的多个版本,通过时间戳进行索引
- timestamp可以由bigtable设置,也可以由客户端指定
- 版本按timestamp从大到小排序,版本大的先读取
- 为了减小版本维护成本,有两种 column-family 维度的 版本回收策略
- 客户端可以指定只保留最近N个版本
- 或者自定义一个方法?足够新的数据才保存(比如近7天的版本)
API 提供的API Link to heading
略
Building Blocks 资源结构依赖 Link to heading
- 存储:GFS
- 存储数据、日志文件
- 调度系统:K8S类似
- 调度任务、管理资源、系统监控、故障处理
- 文件格式:Google SSTable 见leveldb
- 底层存储文件的存储格式,按block存储数据,封装基本操作,有cache机制加快访问速度
- 锁服务:Chubby 强依赖(chubby可用性上,2006年的论文中提供的数据并非100%可靠),用途如下
- 确保某个时刻最多只有一个master
- 存储bootstrap location
- tablet server的注册与发现、生命周期管理
- 存储schema信息,如column family信息
- 存储access control访问控制列表
实现 Link to heading
三部分组件 Link to heading
- client lib
- 封装好的SDK
- 直接和tablet server通信,不依赖master提供tablet位置信息
- one master server
- 负责分配tablet给tablet server
- 检测tablet servers的增减
- 平衡负载
- 回收GFS中的文件(删除文件)
- 处理schema变化,如table创建、column family创建
- many tablet servers
- 可动态增减
- 管理多个tablets 每个server 10到1000个 tablet
- 处理对tablet的读写请求
- 分割过大的tablet
- 每个tablet大小在 100-200MB左右
初始状态是 一个table只有一个tablet
Tablet位置信息管理 Link to heading
三层层级结构存储,类似B+树的结构
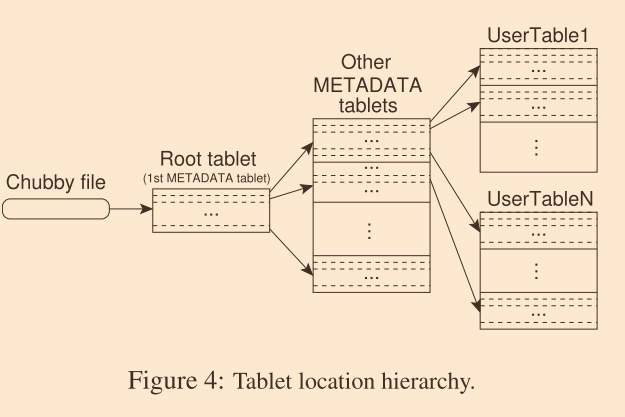
- 第一层
- 存放位置:chubby服务
- 存储信息:root tablet,是一个特殊的table METADATA 众多tablets的第一个,这个tablet存储了这个特殊table对应的所有的tablets的位置信息,被特殊对待,永远不会split
- 第二层
- 存放位置:root tablet 对应的 METADATA table
- 存储信息:row key(tablet对应的 table 标识如表名 和最后一行数据),value:位置信息
- 第三层
- 存放位置:METADATA table中 row 对应的位置信息
- 存储信息:某个table对应的tablet的位置
通过这个设计,在128MB的METADATA大小限制下,可以对 2^34 个tablets进行寻址
客户端获取tablet位置信息
- 缓存tablet位置信息
- 若某个tablet信息未缓存,或者信息不正确,则通过上述层级重新构建客户端缓存
Tablet的管理 Link to heading
组件的关系描述
- tablet server
- 一个tablet由一个tablet server管理,一个tablet server管理多个tablet
- 使用chubby对tablet servers做服务注册&发现,master监控对应目录来发现所有的tablet servers,在chubby中的表示为一个全局唯一的文件
- tablet server从chubby获取排它锁,如果锁丢失则停止对属于该tablet server的tablet提供服务
- 当chubby的锁文件存在时,tablet server会不停的更新排它锁,如果锁文件不存在,tablet server会停止服务,终止进程
- 当tabet server停止时,会尝试释放锁,这样master server会更快的将它的tablets分配出去
- master server
- master server记录所有的tablet servers和tablets映射关系,以及未分配的tablets
- 当一个tablet没有被分配,且有一个tablet server有足够的空间时,master server对这个tablet server发起一个tablet load请求
- 负责监测tablet server的状态,并尽快将停止的tablet server对应的tablets分发出去
- tablet server监测是通过周期性的询问每个tablet server当前锁状态,如果tablet server返回锁已丢失或者无法访问到tablet server,master会认定tablet server停止服务,并尝试获取在chubby中对应tablet server的文件的排它锁;若master获取锁成功,意味着chubby是ok的,但tablet server要么跪了要么连接不到chubby,此时master确信该tablet server无法对它所属的tablet提供服务,从而删掉对应的chubby文件
- 一旦tablet server的chubby文件被删除,master可以将其对应的tablets映射关系移动到未分配的tablets类别中,进行重新分配
- 为了确保master与chubby间的网络访问不受网络问题影响,如果master的chubby session过期,master会终止自己,master故障不影响现有的tablet和tablet server的映射关系,只是没有继续更新映射关系而已
- master server记录所有的tablet servers和tablets映射关系,以及未分配的tablets
- master server启动过程
- 获取chubby中唯一的master文件的排他锁 避免同时启动多个master
- 扫描chubby中的tablet server目录以找到运行的tablet server
- 与tablet server沟通 获取tablet server与tablets的映射关系
- 扫描 METADATA table 获取tablets全集,当发现某个tablet没有所属的tablet server,将对应的tablet放到等待分配tablet server的组中
- 扫描过程必须发生在 METADATA table 的所有tablets都分配给tablet server后,因此如果root tablet没有对应的tablet server,那么master将root tablet添加到待分配tablet server的组中,因为root tablet包含所有METADATA对应的tablets的id,所以当master扫描一次root tablet之后就知道所有的METADATA对应的tablets是否被分配出去
- tablet的分裂
- 当某个tablet太大超过阈值时会进行分裂,由tablet server发起,分裂完成后通知master server
- 通知可能会丢失,所以master也有主动询问的机制,在master向tablet发起load tablet请求时,tablet server
Tablet关键过程 Link to heading
- tablet的恢复
- tablet server从METADATA中读取元信息,包含SSTable文件列表和redo位置
- 先加载SSTables的索引到内存中
- 然后加载redo位置之后的所有写操作到内存的memtable中
- tablet写入
- tablet server接收客户端的写入请求,合法性&权限校验
- 权限映射放在chubby中
- 写入请求先到redo log中,再到内存中的memtable
- tablet server接收客户端的写入请求,合法性&权限校验
- tablet读取
- tablet server接收客户端的读取请求,合法性&权限校验
- 读取先读内存中的memtable 再找SSTable文件
Compaction Link to heading
- minor compaction
- 操作:内存中的memtable大小达到阈值,会dump成SSTable写到GFS中
- 目标
- 降低tablet server的内存使用量
- 降低tablet恢复时所需要读取的redo log量(因为SSTable已经持久化,读取redo log只是恢复内存中未持久化的数据)
- merging compaction (这个和leveldb 的major compaction类似)
- 操作:部分SSTable以及内存中的memtable多路归并为一个SSTable
- 目标
- 减少SSTable文件数,减少IO次数,提高读取速度
- major compaction (和leveldb中的不太一样,Bigtable中的major compaction 是一个 full compaction,将所有的SSTable多路归并为一个SSTable)
- 操作:所有SSTable多路归并为一个SSTable
- 目标
- 减少SSTable文件数,减少IO次数,提高读取速度
- 彻底删除有deleted标识的key,第一次delete只是加了个标识,major compaction才会真正删除数据
优化手段归纳 Link to heading
locality group Link to heading
- 客户端可以把多个 column families 分组成为一个locality group,对locality group会生成一个单独的SSTable,以提高读相同locality group下多个column的速度
- locality group提供更高级的调优参数,如内存cache
Compression Link to heading
- 客户端可以指定是否压缩以及压缩格式,可针对不同类型数据做不同的处理
read cache Link to heading
tablet server支持两层cache
- scan cache 缓存 key-value 对;可以提高热key访问速度
- block cache 缓存SSTable blocks;可以提高范围访问速度
Bloom filters Link to heading
- 快速判断某个row/column对是否在某个SSTable中,减少文件读取数量,减少IO次数
- 极大提高读取不存在的 row/column 的速度
Commit-log优化 Link to heading
- 一个tablet server下管理多个tablet,所有tablet的commit log都写到同一个GFS文件中,减少文件数
- 坏处 在recovery阶段引入复杂度
- 当某个tablet server挂了,tablets会被重新分配到其它tablet server,通常一个tablet server会被分配部分tablets,这时合并后的commit log中就会包含其它tablets的commit log数据,造成recovery慢以及读取没用数据的问题
- 解法:先sort再读取,sort顺序 <table, row name, log seq number>,sort也是并行进行的,由master server进行统一协调
- 坏处 在recovery阶段引入复杂度
- GFS写毛刺优化,通过线程池(两个线程)
Tablet Recovery提速 Link to heading
- master移动tablet前,原来的tablet server先进行一次minor compaction,将内存中的数据尽可能多的持久化到SSTable中
- 原来的tablet server停止服务后,unload之前,再进行一次minor compaction,将所有内存数据都持久化到SSTable中,避免了tablet move后需要读取redo log数据进行内存memtable重建
immutability 不可变 Link to heading
- memtable row 采用 copy-on-write 机制,读写并行进行
- immutable避免了很多并发更新的问题
- immutable SSTable可以提高tablet split的速度,子tablet可以共享父tablet的SSTable
性能评估 Link to heading
略
案例介绍 Link to heading
略
经验教训 Link to heading
- 遇到的错误种类比想象的多,对系统持续更新升级,没有一劳永逸的设计
- 加新特性一定要慎重,要根据真实使用场景来设计
- 系统监控很重要
- simple design的价值